Стоп-слова — это набор часто встречающихся слов, которые, обычно, не имеют большого значения для смысла текста. К ним относятся предлоги, союзы, артикли, местоимения и другие вспомогательные слова.

Исследования в области SEO, трафик и техничка


Стоп-слова — это набор часто встречающихся слов, которые, обычно, не имеют большого значения для смысла текста. К ним относятся предлоги, союзы, артикли, местоимения и другие вспомогательные слова.
Кратко и быстро рассмотрим, что же это такое — вертикальные и горизонтальные отклонения. Приведу примеры, в том числе и с первым порядком.
Читать далее «Что такое вертикальное и горизонтальное отклонение в SEO?»Бывают моменты, когда хочется посмотреть, каких страниц больше нет на сайте. Для чего это надо? Ну, например:
Часто работаю с сервисом xmlriver.com для парсинга выдачи Google и Yandex.
Читать далее «Пакет под Python для парсинга Yandex/Google»
Различные сервисы по нейронным сетям постоянно обучают свои модели и обновляют базы знаний.
Если вы не хотите делиться информацией со своейго сайта, то можете заблокировать их через файл robots.txt. Ниже рассмотрим пример такого файла.
Скрипт неплохо подходит для кластеризации/чистки SEO ключей (семантического ядра). Поддерживает множество языков, имеется много бесплатных моделей.
Он кластеризует ключи (фразы) на основе заданного порога семантической близости и минимального количества «соседей» для создания кластера.
Читать далее «Кластеризация ключей на основе близости фраз [Python]»Дело было вечером, делать было нечего…
К сожалению, на PHP нет нормальной многопоточности, поэтому быстро накатал рекурсивный парсинг страниц сайта из XML карты по заданному списку доменов на Python.
Скрипт сам ищет карту сайта и парсит ее, включая вложенные карты сайте, если они есть.
Читать далее «Рекурсивный парсинг URL адресов из sitemap.xml на Python»Сегодня увидел один интересный лайфхак в канале Mike Blazer (ищите ссылку на него и другие источники на странице источников по SEO).
Пример демонстрации на видео
Чтобы узнать как часто приходит к вам Гугл бот — откройте GSC (Google Search Console) и внизу откройте раздел Settings (Настройки). Там можно открыть отчет по скорости сканирования вашего сайта.
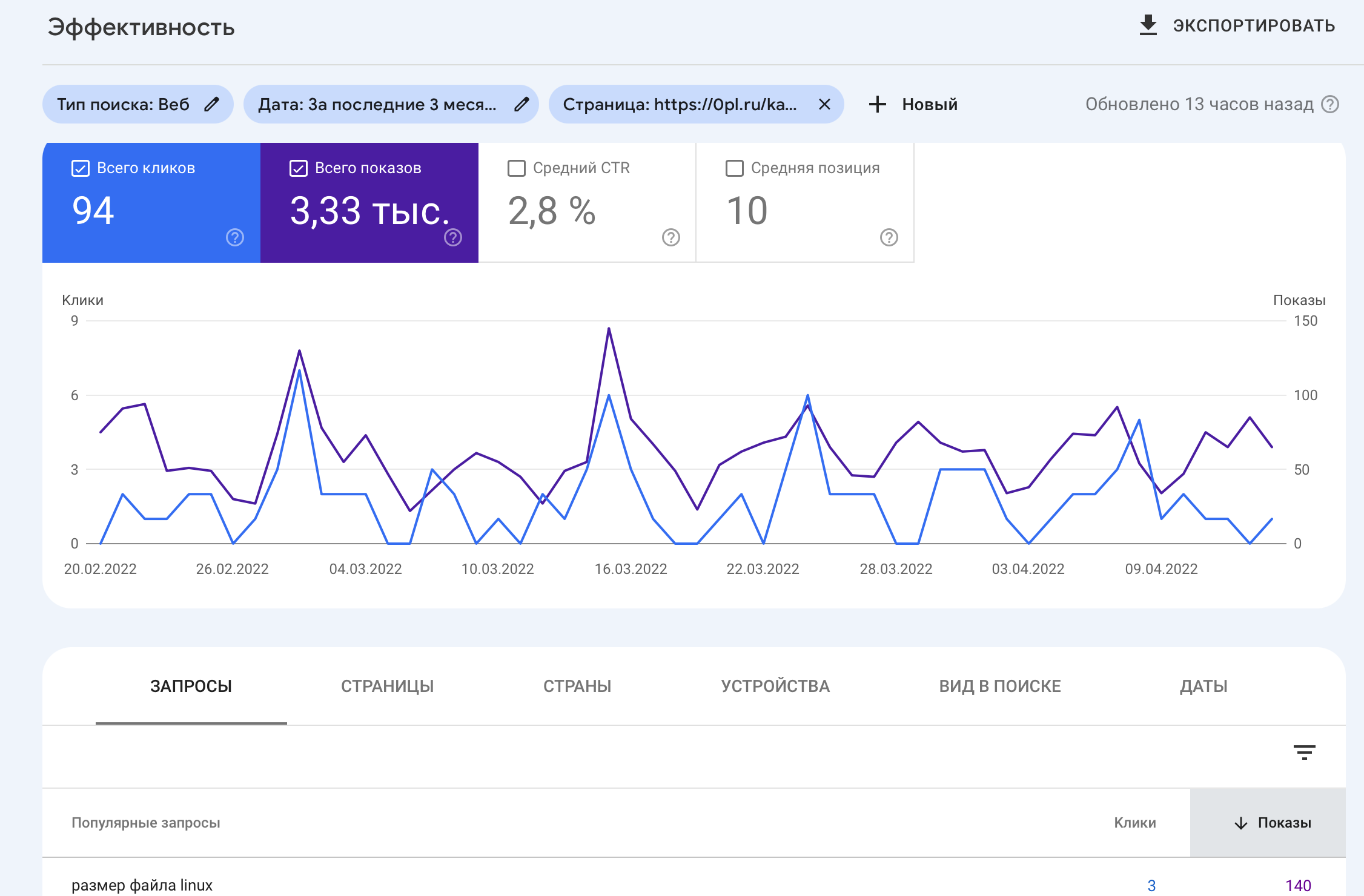
Читать далее «Заметки и лайфхаки по Google Search Console»Пока писал другой пост, нужно было зайти в Google Search Console и возникла идея провести короткий эксперимент. Есть старый пост в моем блоге.
На 16 апреля в Google Search Console показывает, что есть неплохие показы, но низкая позиция и слабый CTR:
Интересную я тут статью нашел от Мэта Каттса, которую он отправлял библиотекарям о том, как Google собирает и ранжирует результаты.
Статья вскоре была удалена, но Интернет все помнит.
Читать далее «Как Google собирает и оценивает результаты?»Интересные заметки о важных сигналах, которые влияют на ранжирование в Google от человека, который годами занимается SEO: от изучения и тестирования патентов алгоритмов поиска и ранжирования Google, Yahoo, Bing до самостоятельного профессионального продвижения сайтов.
Читать далее «20 Сигналов траста (рейтинга) сайтов в Google»Сегодня нашел интересный ресурс, на котором ребята проводят различные тесты. По возможности, буду обновлять этот пост. А вот интересные выводы:
Читать далее «Выводы из экспериментов по SEO»С сожалением узнал, что популярная программа Page Weight Desktop больше не поддерживается, поэтому считать внутренний PageRank не так удобно теперь.
Конечно, есть, например, способ рассчета в программах:
Читать далее «Еще один способ расчета внутреннего PageRank»Часто вебмастера используют тег robots «noindex, follow», чтобы исключить страницу из индекса, но чтобы робот гулял по ссылкам с этой страницы и учитывал вес. Для продвижения в Google такой вариант не стоит использовать!
Читать далее «Стоит ли использовать noindex тег?»